ChatGLM-6B 是清华开源的一个小型对话模型,让大家可以在自己部署起来跑一跑看看效果。但对于本身不是从事此类工作的其他研发伙伴来说,部署这个东西多半都会卡在环境上。所以小傅哥在本地/云服务部署体验后,把相关经验分享下,让有需要的伙伴也可以尝尝鲜。
一、模型简述
二、基础环境
- 1.服务配置
- 2.工程代码
- 3.算法模型
- 4.软件版本
- 5.软件卸载
三、环境配置 - 服务器版本
- 步骤1:环境安装
- 步骤2:代码下载
- 步骤3:模型下载
- 步骤4:安装配置
- 步骤5:启动执行
四、环境配置 - AIGC版本
- 1.注册服务
- 2.选择服务
- 3.配置环境
- 4.控制平台
- 5.初始配置
- 6.启动服务
- 7.访问服务
五、环境配置 - Docker 版本
- 1.编写
DockerFile文件 - 2.编写
Docker-Compose文件 - 3.搭建步骤
- 1.编写
ChatGLM-6B 开源双语对话语言模型,太牛皮了!我要能做一个这个水平的东西,我就AI创业,融资、赚钱、发财,躺平去!哈哈哈!—— 真好,看到这样一个东西,感觉看到了国内 AI 的希望!感谢清华 ChatGLM 团队。
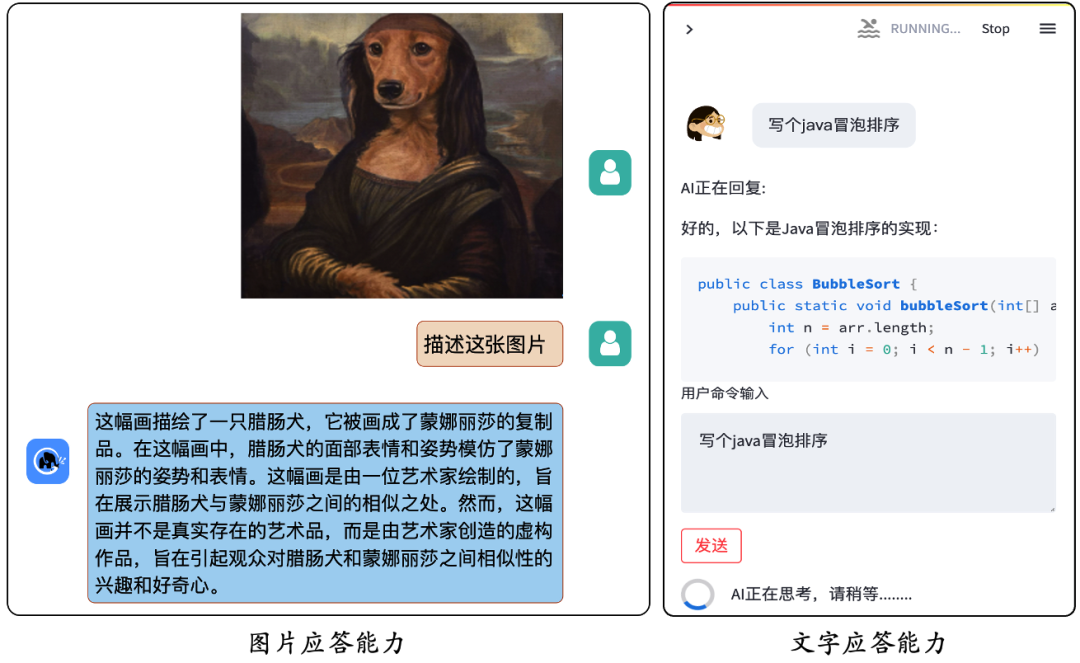
一、模型简述
ChatGLM 参考了 ChatGPT 的设计思路,在千亿基座模型 GLM-130B 中注入了代码预训练,通过有监督微调(Supervised Fine-Tuning)等技术实现人类意图对齐。2022年11月,斯坦福大学大模型中心对全球30个主流大模型进行了全方位的评测,GLM-130B 是亚洲唯一入选的大模型👍🏻。

同时 ChatGLM 团队为与社区一起更好地推动大模型技术的发展,清华开源了 ChatGLM-6B 模型。它是一个初具中文问答和对话功能的小型模型,可以让大家即使在本地和一些小型的服务器上就可以部署体验。
- 源码:https://github.com/THUDM/ChatGLM-6B - 这里有最新更新的内容和部署说明
- 社区:https://chatglm.cn/blog - 这里有更全面的介绍信息
二、基础环境
1. 服务配置
ChatGLM-6B 虽然已经是很温馨提供的,能最佳支持对话的最小模型了,但实际部署的时候仍需要一个不小的服务器32G内存配置或者有较好的16G NVIDIA显卡。可能就怕大家部署起来,所以官网上也提供了更低成本的部署方案,INT8和INT4 数据模型。整体所需空间如下;
| 量化等级 | 最低 GPU 显存(推理) | 最低 GPU 显存(高效参数微调) |
|---|---|---|
| FP16(无量化) | 13 GB | 14 GB |
| INT8 | 8 GB | 9 GB |
| INT4 | 6 GB | 7 GB |
小傅哥自己也是在 Mac M1、轻量云主机,还有一个专门用于测试AIGC的服务器上,都做了测试验证,这样也能避免大家走弯路。就像我在一款8G内存的轻量云主机上,部署 INT4 模型,报错如下;
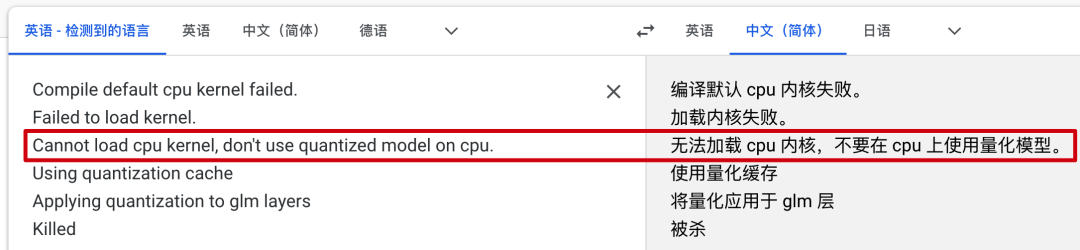
😂 所以别买一些配置不佳的机器,否则你根本跑不起来,还浪费钱。
2. 工程代码
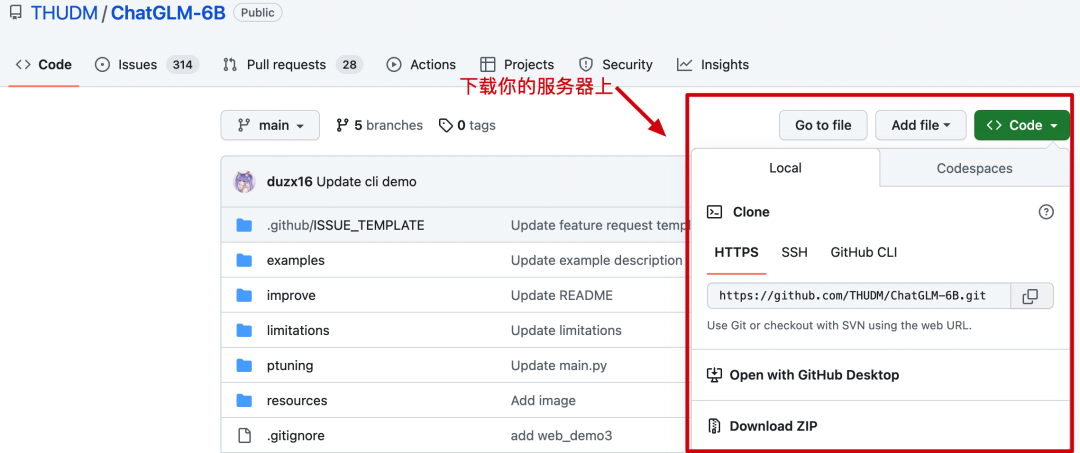
源码:https://github.com/THUDM/ChatGLM-6B - 无论你使用哪种部署方式,都需要把代码下载到对应的服务上。
3. 算法模型
在 ChatGLM-6B 中有一段代码是配置模型地址的,除了说明的Mac电脑,理论上来说它可以自动下载。但这些模型太大了,所以最好是提前下载到本地使用。
// web_demo2.py 部分代码
tokenizer = AutoTokenizer.from_pretrained("/Users/xfg/develop/github/chatglm-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("/Users/xfg/develop/github/chatglm-6b", trust_remote_code=True).half().cuda()

官网:https://huggingface.co/ - 提供模型下载,按照你的需要下载对应的测试模型到服务器上;
- chatglm-6b:https://huggingface.co/THUDM/chatglm-6b/tree/main
- chatglm-6b-int4:https://huggingface.co/THUDM/chatglm-6b-int4/tree/main
- chatglm-6b-int8:https://huggingface.co/THUDM/chatglm-6b-int8/tree/main
- visualglm-6b:https://huggingface.co/THUDM/visualglm-6b/tree/main - 用于图形识别的模型,在镜像中还没有。
镜像:https://cloud.tsinghua.edu.cn/d/674208019e314311ab5c/?p=%2F&mode=list - 镜像的下载速度比较快。注意:镜像中没有基础的内容,需要从官网下载。
- chatglm-6b:https://cloud.tsinghua.edu.cn/d/674208019e314311ab5c/?p=%2Fchatglm-6b&mode=list
- chatglm-6b-int4:https://cloud.tsinghua.edu.cn/d/674208019e314311ab5c/?p=%2Fchatglm-6b-int4&mode=list
- chatglm-6b-int8:https://cloud.tsinghua.edu.cn/d/674208019e314311ab5c/?p=%2Fchatglm-6b-int8&mode=list
4. 软件版本

- macOS 12.3 或更高版本 - https://developer.apple.com/metal/pytorch
- Python 3.10.8 或更高版本 - 因为有些聊天的界面模块,需要这个版本。
5. 软件卸载
# 1. 卸载 python3/python 注意先看下版本 python -V 确认下名称是 python 还是 python3 以及 pip
whereis python3 |xargs rm -frv
rm -rf /usr/local/bin/python3 /usr/local/bin/pip3
# 2. 卸载 openssl - 如果安装了老版本的python,又安装新的,可能需要卸载 ssl 重新安装
whereis openssl |xargs rm -frv
- 如果你的电脑或者服务器之前已经安装了 python 那么可以先把它卸载掉。
三、环境配置 - 服务器版本
以能运行起 ChatGLM-6B 只需要以下5个步骤;

只要你能按照顺序,正确的执行这些步骤,就可以运行起 ChatGLM-6B 模型,接下来就跟着小傅哥的步骤执行吧。注意如果你需要绘图能力,可以在本文学习后。按照官网介绍,替换下模型重新启动即可;https://github.com/THUDM/ChatGLM-6B - [2023/05/17] 发布 VisualGLM-6B 一个支持图像理解的多模态对话语言模型。
步骤1:环境安装
1. openssl
# 1. 卸载openssl
whereis openssl |xargs rm -frv
# 2. 官网下载openssl编译安装
wget http://www.openssl.org/source/openssl-1.1.1.tar.gz
tar zxf openssl-1.1.1.tar.gz
cd openssl-1.1.1
./config --prefix=/usr/local/openssl shared zlib
make && make install
# 3. 设置环境变量 LD_LIBRARY_PATH
echo "export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/openssl/lib" >> /etc/profile
source /etc/profile
# 4. 卸载重新编译安装python3
whereis python3 |xargs rm -frv
rm -rf /usr/local/bin/python3 /usr/local/bin/pip3
mkdir /usr/local/python3
./configure --prefix=/usr/local/python3 --enable-optimizations --with-openssl=/usr/local/openssl
make -j8 && make install
2. Python 3.10
cd ~
# 1.下载Python安装包
wget https://www.python.org/ftp/python/3.10.8/Python-3.10.8.tgz
# 2.将安装包移动到/usr/local文件夹下
mv Python-3.10.8.tgz /usr/local/
# 3.在local目录下创建Python3目录
mkdir /usr/local/python3
# 4.进入的Python安装包压缩包所在的目录
cd /usr/local/
# 5.解压安装包
tar -xvf Python-3.10.8.tgz
# 6.进入解压后的目录
cd /usr/local/Python-3.10.8/
# 7.配置安装目录
./configure --prefix=/usr/local/python3
# 8.编译源码
make
# 9.执行源码安装
make install
# 10.创建软连接
ln -s /usr/local/python3/bin/python3 /usr/bin/python3
# 11. 测试
python3 -V
3. 安装pip3
cd ~
# 1.下载
wget https://bootstrap.pypa.io/get-pip.py
# 2.安装;注意咱们安装了 python3 所以是 pyhton3 get-pip.py
python3 get-pip.py
# 3.查找pip安装路径
find / -name pip
# 4.将pip添加到系统命令
ln -s /usr/local/python/bin/pip /usr/bin/pip
# 5.测试
pip -V
# 6.更换源,如果不更换那么使用 pip 下载软件会很慢
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
pip config set install.trusted-host mirrors.aliyun.com
pip config list
# pip国内镜像源:
# 阿里云 http://mirrors.aliyun.com/pypi/simple/
# 中国科技大学 https://pypi.mirrors.ustc.edu.cn/simple/
# 豆瓣 http://pypi.douban.com/simple
# Python官方 https://pypi.python.org/simple/
# v2ex http://pypi.v2ex.com/simple/
# 中国科学院 http://pypi.mirrors.opencas.cn/simple/
# 清华大学 https://pypi.tuna.tsinghua.edu.cn/simple/
4. 安装git
cd ~
# 1.安装前首先得安装依赖环境
yum install -y perl-devel
# 2.下载源码包到 CentOS 服务器后进行解压
wget https://mirrors.edge.kernel.org/pub/software/scm/git/git-2.9.5.tar.gz
tar -zxf git-2.9.5.tar.gz
cd git-2.9.5
# 3.执行如下命令进行编译安装
./configure --prefix=/usr/local/git
make && make install
# 4.添加到系统环境变量
vim ~/.bashrc
export PATH="/usr/local/git/bin:$PATH"
# 5.使配置生效
source ~/.bashrc
# 6.测试
git version
步骤2:代码下载
在Linux服务器,可以直接在 cd ~ 目录下执行;git clone git://github.com/THUDM/ChatGLM-6B.git
步骤3:模型下载
可以从官网:https://huggingface.co/THUDM/chatglm-6b/tree/main 或者清华的镜像仓库下载 https://cloud.tsinghua.edu.cn/d/fb9f16d6dc8f482596c2/ - 如果你需要其他模型,可以在目录:基础环境中找到。
本地直接环境直接下载,网络环境可以通过 SFTP - Termius 传到一个 ChatGLM-6B/data 目录下。或者直接通过 wget http://... 这样的命令方式直接下载模型。会需要较长的耗时
步骤4:安装配置
# sudo su - 切换到root 或者通过 sudo 执行。镜像可以换一换,看看哪个快用哪个。
sudo pip install -r requirements.txt -i https://mirror.baidu.com/pypi/simple
# 执行成功案例 - 过程较长
Looking in indexes: https://mirror.baidu.com/pypi/simple
Collecting protobuf
Downloading https://mirror.baidu.com/pypi/packages/06/38/e72c556c25aaaaafca75018d2d0ebc50c5ab80983dd4def086624fba43f2/protobuf-4.23.0-cp37-abi3-manylinux2014_x86_64.whl (304 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 304.5/304.5 KB 19.4 MB/s eta 0:00:00
Collecting transformers==4.27.1
Downloading https://mirror.baidu.com/pypi/packages/6d/9b/2f536f9e73390209e0b27b74691355dac494b7ec8154f3012fdc6debbae7/transformers-4.27.1-py3-none-any.whl (6.7 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 6.7/6.7 MB 10.4 MB/s eta 0:00:00
- 对于本地的网络和普通的服务器,这个步骤会执行较长的时间。如果执行失败了,在此继续执行就可以,直至得到上天的眷顾,你成功了!!!
步骤5:启动执行
# 切换到 ChatGLM-6B 工程目录,执行
python3 -m streamlit run ./web_demo2.py --server.port 7397 --server.address 0.0.0.0
# 执行结果 - 成功后有这样的效果
Collecting usage statistics. To deactivate, set browser.gatherUsageStats to False.
You can now view your Streamlit app in your browser.
URL: http://0.0.0.0:7397
Explicitly passing a `revision` is encouraged when loading a model with custom code to ensure no malicious code has been contributed in a newer revision.
Explicitly passing a `revision` is encouraged when loading a configuration with custom code to ensure no malicious code has been contributed in a newer revision.
Explicitly passing a `revision` is encouraged when loading a model with custom code to ensure no malicious code has been contributed in a newer revision.
Loading checkpoint shards: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████| 8/8 [01:30<00:00, 11.35s/it]
- 你可以指定端口,并对端口开放访问权限。之后就可以反问地址;
http://你的服务器地址:端口 - 初次使用的时候,会进行模型的启动,也就是这个阶段,很多配置不佳的服务器是没法启动成功的。
四、环境配置 - AIGC版本
这是一个钞能力版本,你只需要花钱到位,体验个几小时,那么这个是最节省成本的。你可以通过我的邀请链接进入,这样会得到一些使用配额,可能不需要花钱。
1. 注册服务
地址:https://www.lanrui-ai.com/register?invitation_code=3931177594
后台:https://www.lanrui-ai.com/console/workspace
2. 选择服务

- ¥1.90/时,不确定一直有。同配置的4.9元每小时。从你购买启动开始计费,安装环境较好时,整个过程需要大概需要20元左右,能体验到。
3. 配置环境

- 创建服务后,运行镜像选择;pytorch -> cuda 最后这个版本。
- 预训练模型选择 chatglm-6b 这样你也不需要自己下载模型数据了。
4. 控制平台


- 从工作空间进入到控制台,你可以分别
从 data 看到 ChatGLM-6B 的代码在imported_models 看到预训练模型 chatglm-6b
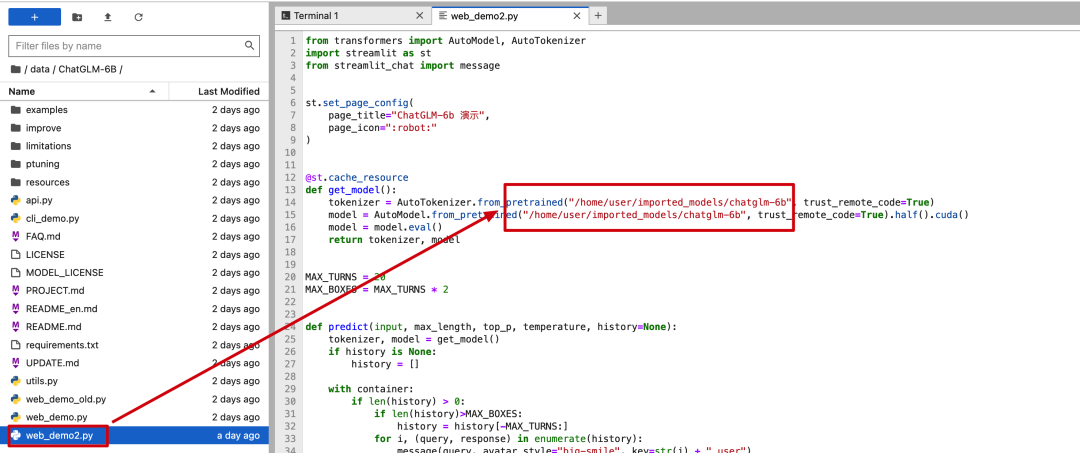
- 检查工程 web_demo2.py 中加载模型的路径是否正确,如果不对需要修改。
- 如果你的服务中,没有默认下载或者需要重新下载。那么你可以安装 git 指令,下载代码到 data 仓库即可。
5. 初始配置

user@lsp-ws:~/data$ sudo su
root@lsp-ws:/home/user/data# cd ChatGLM-6B/
root@lsp-ws:/home/user/data/ChatGLM-6B# pip install -r requirements.txt
- 这个安装速度会非常快,几乎不需要太久的等待。
6. 启动服务

python3 -m streamlit run ./web_demo2.py --server.port 27777 --server.address 0.0.0.0
- 另外 ChatGLM-6B 还提供了命令行测试
python cli_demo.py和 API 启动python api.py
curl -X POST "http://127.0.0.1:8000" \
-H 'Content-Type: application/json' \
-d '{"prompt": "你好", "history": []}'
7. 访问服务

- 回到控制台复制调试地址,即可访问;
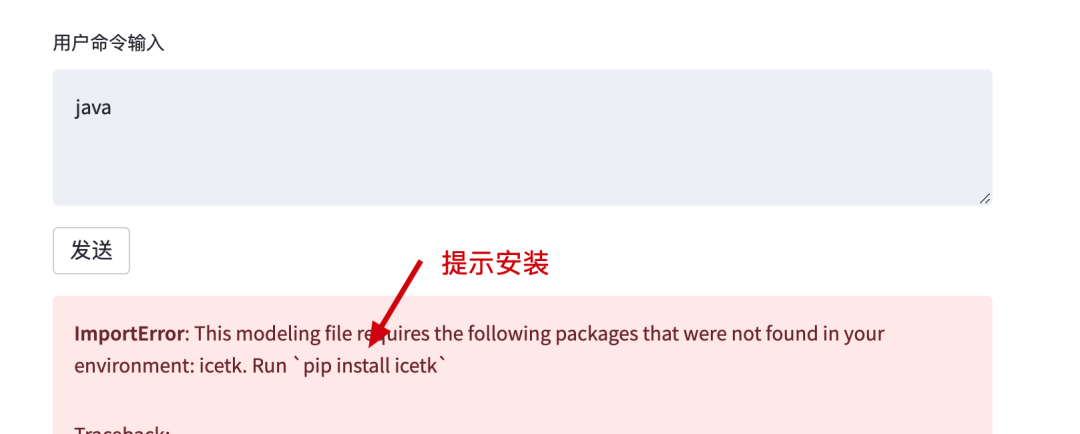
- 如果你报错了,那么在控制台执行安装即可。
control + c停止服务,执行pip install icetk- 再次执行步骤6启动服务,现在在访问。
python3 -m streamlit run ./web_demo2.py --server.port 27777 --server.address 0.0.0.0

- 初次运行,它会加载模型。在控制台可以看到加载的模型进度,大概几分钟就加载好了。
- 看到控制台的模型加载完毕后,再次点击下发送 好了,到你也可以测试下发送其他的内容,进行体验。
五、环境配置 - Docker 版本
在官网的地址中还看到了一个 Docker 的配置方式,我把它引入过来,方便有需要的伙伴进行操作。原文地址:https://www.luckzym.com/posts/e95da08c/
1. 编写DockerFile文件
# 设置基础映像
FROM nvidia/cuda:11.8.0-cudnn8-devel-ubuntu22.04
# 定义构建参数
# 例如ARG USER=test为USER变量设置默认值"test"。
ARG USER=test
ARG PASSWORD=${USER}123$
# 处理讨厌的 Python 3 编码问题
ENV LANG C.UTF-8
ENV DEBIAN_FRONTEND noninteractive
ENV MPLLOCALFREETYPE 1
# 更新软件包列表并安装软件属性通用包
RUN apt-get update && apt-get install -y software-properties-common
# 添加Python ppa,以便后续安装Python版本
RUN add-apt-repository ppa:deadsnakes/ppa
# 安装Ubuntu的常用软件包,包括wget、vim、curl、zip、unzip等
RUN apt-get update && apt-get install -y \
build-essential \
git \
wget \
vim \
curl \
zip \
zlib1g-dev \
unzip \
pkg-config \
libgl-dev \
libblas-dev \
liblapack-dev \
python3-tk \
python3-wheel \
graphviz \
libhdf5-dev \
python3.9 \
python3.9-dev \
python3.9-distutils \
openssh-server \
swig \
apt-transport-https \
lsb-release \
libpng-dev \
ca-certificates &&\
apt-get clean &&\
ln -s /usr/bin/python3.9 /usr/local/bin/python &&\
ln -s /usr/bin/python3.9 /usr/local/bin/python3 &&\
curl https://bootstrap.pypa.io/get-pip.py -o get-pip.py &&\
python3 get-pip.py &&\
rm get-pip.py &&\
# 清理APT缓存以减小Docker镜像大小
rm -rf /var/lib/apt/lists/* /tmp/* /var/tmp/*
# 设置时区
ENV TZ=Asia/Seoul
RUN ln -snf /usr/share/zoneinfo/$TZ /etc/localtime && echo $TZ > /etc/timezone
# 为应用程序创建一个用户
RUN useradd --create-home --shell /bin/bash --groups sudo ${USER}
RUN echo ${USER}:${PASSWORD} | chpasswd
USER ${USER}
ENV HOME /home/${USER}
WORKDIR $HOME
# 安装一些Python库,例如numpy、matplotlib、scipy等
RUN python3 -m pip --no-cache-dir install \
blackcellmagic\
pytest \
pytest-cov \
numpy \
matplotlib \
scipy \
pandas \
jupyter \
scikit-learn \
scikit-image \
seaborn \
graphviz \
gpustat \
h5py \
gitpython \
ptvsd \
Pillow==6.1.0 \
opencv-python
# 安装PyTorch和DataJoint等其他库
# 其中torch==1.13.1表示安装版本为1.13.1的PyTorch
RUN python3 -m pip --no-cache-dir install \
torch==1.13.1 \
torchvision==0.14.1 \
torchaudio==0.13.1 \
'jupyterlab>=2'
RUN python3 -m pip --no-cache-dir install datajoint==0.12.9
# 设置环境变量LD_LIBRARY_PATH,以便支持性能分析库
ENV LD_LIBRARY_PATH /usr/local/cuda/extras/CUPTI/lib64:${LD_LIBRARY_PATH}
# 启动ssh服务器,打开22号端口
USER root
RUN mkdir /var/run/sshd
EXPOSE 22
CMD ["/usr/sbin/sshd", "-D"]
2. 编写Docker-Compose文件
version: "3.9"
services:
nvidia:
build: . # 告诉Docker Compose在当前目录中查找Dockerfile并构建镜像
runtime: nvidia # 启用nvidia-container-runtime作为Docker容器的参数,从而实现对GPU的支持
environment:
- NVIDIA_VISIBLE_DEVICES=all # 设置所有可用的GPU设备
ports:
- "22:22" # port for ssh
- "80:80" # port for Web
- "8000:8000" # port for API
tty: true # 创建一个伪终端以保持容器运行状态
3. 搭建步骤
3.1 准备Docker容器&AI模型文件
- 修改
Docker Compose文件,添加volumes路径
version: "3.9"
services:
nvidia:
build: . # 告诉Docker Compose在当前目录中查找Dockerfile并构建镜像
runtime: nvidia # 启用nvidia-container-runtime作为Docker容器的参数,从而实现对GPU的支持
environment:
- NVIDIA_VISIBLE_DEVICES=all # 设置所有可用的GPU设备
ports:
- "22:22" # port for ssh
- "80:80" # port for Web
- "8000:8000" # port for API
tty: true # 创建一个伪终端以保持容器运行状态
# 添加一个和宿主机连接的路径
volumes:
- ./:/data
- 下载对应的AI模块文件
从Hugging Face Hub下载所需要的模型,由于我使用的显卡只有8G显存,所以直接下载了INT4量化后的模型。
AI模型下载地址:
- THUDM/chatglm-6b
- THUDM/chatglm-6b-int4
- THUDM/chatglm-6b-int8
这里推荐使用Git工具进行拖拽对应的仓库,在拖拽前记得给Git工具安装上Git LFS。
仓库存储的地方就放在我当前创建Docker Compose文件目录下,这样刚好可以利用volumes将其映射进容器中。
# Make sure you have git-lfs installed (https://git-lfs.com)
git lfs install
git clone https://huggingface.co/THUDM/chatglm-6b-int4
# if you want to clone without large files – just their pointers
# prepend your git clone with the following env var:
GIT_LFS_SKIP_SMUDGE=1
3.2 准备ChatGLM-6B并运行
- 拉取官方
ChatGLM-6B项目仓库文件
git clone https://github.com/THUDM/ChatGLM-6B.git
仓库存储的地方依旧是当前创建Docker Compose文件目录。如果大家不希望存放在该目录下可以自行修改一下Docker Compose中的volumes映射路径。
- 拉起该深度学习
Docker容器
docker-compose up --build -d
- 进入容器中
# 查看刚刚启动的深度学习容器的ID号
docker ps
# 进入容器内部
docker exec -it xxxxxxx /bin/bash # xxxxxxx 是PS后容器的CONTAINER ID号
- 安装项目依赖
# cd到刚刚拖拽下来的项目仓库中
cd /data/ChatGLM-6B
# 安装项目依赖文件
pip install -r requirements.txt
- 修改本地AI模型路径
在这里我们使用官方提供的命令行Demo程序来做测试。
# 打开cli_demo.py文件对其进行修改
VI cli_demo.py
# 修改第6、第7行的代码,将原有的模型名称修改为本地AI模型路径
# 修改结果如下,其中/data/chatglm-6b-int4为你本地AI模型的路径地址
tokenizer = AutoTokenizer.from_pretrained("/data/chatglm-6b-int4", trust_remote_code=True)
model = AutoModel.from_pretrained("/data/chatglm-6b-int4", trust_remote_code=True).half().cuda()
- 运行仓库中命令行Demo程序:
python cli_demo.py
不出意外,在命令执行完之后你将可以体验到清华开源的ChatGLM-6B自然语言模型了。
原文:https://mp.weixin.qq.com/s/dIsANmzmJu0a8pl138kyQQ